Vivimos en años de avance tecnológico, años de automatización; donde tareas humanas están siendo llevadas a cabo por maquinas o soportadas por ellas. Con estos avances, muchos términos han ganado popularidad: Big Data, machine learning, inteligencia artificial, deep learning, redes neuronales entre otros. Estos términos son populares, porque mas allá de ser una moda, han demostrado su aplicación en problemas reales. Hoy quiero traer un nuevo término Procesamiento del Lenguaje Natural o NLP por sus siglas en ingles.
¿Qué es NLP?
NLP es un área de la computación que busca analizar, modelar y entender el lenguaje humano, una tarea bastante difícil si lo pensamos un momento. ¿Has considerado como nuestro cerebro interpreta el lenguaje? ¿Como somos capaces de comunicarnos? Si tuviéramos claro este punto, ¿como podríamos llevar este conocimiento tácito a reglas explícitas que pudieran ser programadas en una máquina? Lo que antes parecía solo ciencia ficción ahora nos rodea todos los días y veremos por que.
Si has pronunciado las palabras “Hola Siri” ya has visto los beneficios de NLP de primera mano; claro está, puede que prefieras otra marca como Android, Microsoft, Amazon; indistintamente de si te diriges al asistente de Google, Alexa o Cortana, estas dando instrucciones que son interpretadas por una máquina. ¿Como funciona entonces NLP? Para entender esto, debemos entender como se estructura el lenguaje humano.
De vuelta al colegio
El lenguaje es como un conjunto enorme de piezas que podemos combinar para crear estructuras hermosas y gigantes. Para lograr estas estructuras, combinamos las piezas mas pequeñas para crear bloques de un tamaño un poco mayor. La combinación de piezas sigue ciertas reglas, y dichas reglas dependen de si estamos trabajando con las piezas mas pequeñas o con las que hemos construido a partir de estas. Las piezas mas pequeñas son denominadas fonemas, que en la práctica son las letras del alfabeto (A-Z). Las letras por si solas no logran tener un significado, así que comenzamos a combinarlas.
Los siguientes bloques se denominan morfemas, estos son la combinación minima de fonemas que logra tener un significado, de manera común las denominamos palabras, sin embargo, no todos los morfemas se consideran palabras, tal es el caso de prefijos (aero, anti, macro, infra) y sufijos (arquía, ito, ita, filia).

Los lexemas son variaciones de los morfemas que comparten un significado común y en general, una raíz común; por ejemplo “encontrar”, “encontrando”, “encontrado”, “encontraste” comparten la raíz “encontrar”. Este concepto es particularmente importante en fases de NLP, dado que el texto a analizar suele tener distintos lexemas que confluyen al mismo significado y construyen el mismo contexto. El proceso de extraer la raíz común de los lexemas (o lemma) es llamado lematización, trabajar con la raíz de los lexemas permite resumir el texto y facilita el análisis.
Al combinar lexemas y morfemas, se obtienen frases y oraciones; existen ciertas reglas para estas combinaciones, pues no escribimos de manera aleatoria. Un ejemplo común de una oración bien formada suele tener un sustantivo, un verbo y proposiciones que los unen como en: “Javier toca la guitarra en las noches”. El conjunto de leyes que rigen el orden de las palabras es denominado sintaxis.
A partir de la combinación de frases y oraciones, nacen las grandes creaciones que amamos: libros, poemas, canciones, etc. En este nivel existe un contexto y la estructura refleja un significado. Este contexto es el que queremos que sea procesado y entendido por las maquinas.
¿Qué se está haciendo en NLP?
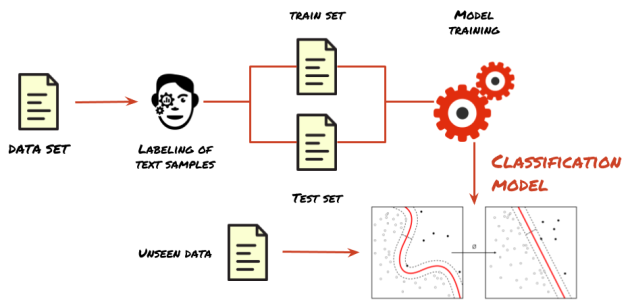
El área mas popular de investigación es clasificación de texto, el objetivo de esta área es asignar una o mas etiquetas a un texto. Un uso común es la detección de spam, usado por compañías como Gmail o Outlook. Otro caso de uso está en el soporte de servicio al cliente; estos equipos deben procesar miles de peticiones/reclamos, no es una tarea eficiente a gran escala, dada la necesidad de interacción humana, además, muchos de los reclamos suelen tener información que no es de valor (solo reflejan insatisfacción pero no el porqué); la clasificación de texto ayuda a filtrar la información que puede llevar a accionables. El proceso para aplicar clasificación de texto es similar al del entrenamiento de un modelo de machine learning, se inicia con un conjunto de datos (texto para el caso puntual), se asignan las etiquetas a cada una de las muestras, se divide el conjunto en entrenamiento y pruebas, se elige un algoritmo de entrenamiento apropiado para el problema y finalmente se entrena el modelo. Luego de la validación del modelo, se usa para clasificar los nuevos datos.

Inicié la definición de NLP dando el ejemplo de Siri, Google assitant, Cortana y Alexa, estos hacen parte del área de agentes conversacionales. En general todas las areas de NLP, tienen en común la extracción de información, el objetivo de esta última es identificar las entidades mencionadas en el texto. Por ejemplo, en una frase como: “El presidente fue al congreso en Bogotá para defenderse de los cargos de corrupción”, para entender el significado, un algoritmo necesitaría extraer palabras como: “presidente”, “congreso”, “Bogotá” y “corrupción”, estas palabras son conocidas como entidades; pueden identificarse fácilmente ya que suelen tomar la forma de sustantivos. Del texto que se encuentra entre las entidades es posible extraer las relaciones: “El presidente fue al congreso”; entidades y relaciones forman un contexto. Un agente conversacional usa el contexto para responder a consultas del usuario, la interpretación de consultas involucra otra área de NLP, information retrieval; ademas de interpretar la consulta, busca dentro de documentos la/s solución/es mas cercana/s a dicha consulta; information retrieval es por supuesto usado en motores de búsqueda. Los agentes conversacionales se apalancan de las áreas mencionadas para dar solución a las peticiones de los usuarios.
A medida que se vuelve mas común la aplicación de NLP, nuevos casos de uso surgen: detección de eventos de calendario en correo electrónico, detección de plagio, reconocimiento de voz, corrección de ortografía, análisis de sentimientos, traducciones; la lista crece a medida que la investigación avanza.
¿Como trabajar con NLP?
Hay tres enfoques para trabajar con NLP, el primero es el uso de heuristicas. Con las heuristicas, las reglas para entender el lenguaje son creadas a mano; el enfoque es de utilidad para MVP’s de aplicaciones, pero es sensible al cambio de contexto (es decir los usuarios dejan de hablar como lo hacían cuando se crearon las reglas) y sufren de perdida de exactitud cuando la aplicación escala. Para trabajar con heuristicas se requiere de expertos en el dominio del problema, esto puede ser una desventaja si lo vemos como una dependencia mas del sistema; para compensar la ausencia del experto, o como una heuristica adicional, se suelen usar bases de conocimiento, diccionarios y tesauros disponibles en la web, estos recursos son mantenidos por la comunidad (en algunos casos) y de acceso libre. Una herramienta común para el análisis en este enfoque son las expresiones regulares, por ejemplo, la siguiente expresión podría usarse para extraer nombres de usuarios al analizar posts en redes sociales:
"@.*"
Un enfoque popular en NLP es el de machine learning; teniendo conjuntos de datos de texto, se entrena un modelo en la tarea deseada; las técnicas mas comunes son: naïve Bayes, support vector machines y conditional random fields. Los conditional random fields o CRF han ganado popularidad superando a los modelos de cadenas de Markov, al dar relevancia al orden de aparición de las palabras y el contexto que forman. CRF ha sido usado de manera exitosa en la extracción de entidades.
Finalmente, deep learning con el uso de redes neuronales es el tercer enfoque, aprovechando la habilidad de las redes neuronales para trabajar con datos sin estructura aparente.
¿Donde puedo iniciar?
Personalmente he trabajado con heuristicas y machine learning, el lenguaje de programación que recomiendo es Python, dada la versatilidad de trabajar con orientación a objetos, programación funcional y estructurada, ademas cuenta con un gran ecosistema para trabajar en ciencia de datos. Las herramientas que seguramente necesitaras son:
- Pandas: Tu mejor amigo manipulando datos. Con pandas es bastante fácil cargar archivos csv y json, con los que seguro tendrás que interactuar, y trabajar con los datos en una estructura de matriz. Permite hacer búsquedas sobre la matriz, transformación, reducción de dimensionalidad, transformación de valores y filtrado entre otras. https://pandas.pydata.org/
- Numpy: Es la herramienta para trabajar con algebra y estructuras de datos de n dimensiones. A medida que avances en el análisis de texto, veras la necesidad de convertir palabras y documentos en vectores, este paquete facilita el trabajo con estas estructuras. https://numpy.org/
- Sklearn: La librería para trabajar con machine learning, tiene una gran cantidad de algoritmos de clasificación, métodos de cluster para aprendizaje no supervisado, preprocesamiento de datos, generación aleatoria de archivos de entrenamiento y pruebas así como funciones de evaluación entre otras cosas. Dominar esta herramienta es la base no solo para NLP sino para los temas que se relacionen con machine learning. https://scikit-learn.org/stable/
- NTLK: Finalmente, el paquete ad hoc package para NLP, provee: clasificación, tokenización, lematización, parseo, diccionarios de stop words y en general un completo set de herramientas para análisis de lenguaje. https://www.nltk.org/
Para leer mas del tema te recomiendo:
- Natural Language Processing Group – Stanford
- Named Entity Recognizer – Stanford
- Information Retrieval – Stanford
- Conditional Random Fields
- Google DialogFlow for conversational agents
Feliz investigación!