We live in years of technologic advance acceleration, years of automation, human tasks are being totally performed by machines or supported by them. With these advances, many terms have gained popularity, words like Big Data, Machine Learning, Artificial Intelligence, Deep Learning, Neural Networks and a long list of etc. Such terms are popular because of how their application in common problems ease our lives. Today I want to bring you a term that may be known by some of you and new to others, Natural Language Processing or NLP.
What is Natural Language Processing?
In short NLP is an area of computer science that seek to analyse, model and understand the human language, hmm an easy task isn`t it? Have you ever thought how to model human language? Or how we take the way we interpret language in our brains, make it explicit rules and wrote those rules as code to be read by a machine? Years ago, this would have seemed science fiction, but nowadays, NLP surround us everyday.
A common phrase related to NLP will be “Hey Siri”; of course, you may posses an Android, but you will communicate with your Google assistant by speaking too and giving instructions which are interpreted on your device. Even if you don’t ask serious questions to your cellphone and just chit chat for fun, the doubt is: how these digital assistants works? How NLP works? The first step to understand this, is to understand how structured language works.
Back to school
Language is like an huge set of lego pieces, which can be combined to create awesome structures; this lego pieces are composed of tinier pieces. Also, there are some rules to combine them, these rules scale up, from the tinier pieces, to the medium, big and to the huge structures you build. The smallest kind of pieces are the characters (A-Z) you call these phonemes. As you know, the phonemes alone are meaningless, so you start to combine them to build bigger blocks.
The next kind of pieces are the morphemes, these are the minimum combination of phonemes that has a meaning to you, you may identify the morphemes as words, but even all words are morphemes, not all morphemes are words, that’s the case of prefixes and suffixes.

Lexemes are variations of morphemes that share common meaning, and in general share a common root; for example, “find”, “finds”, “found” and “finding” share the common root “FIND”. This concept is particularly important in text analysis, since text may have many lexemes, that in the end, refer to a common meaning and a common context. Being able to trace back the lexemes to their root or lemma is called lemmatization and it ease the analysis by leaving the meaningful unit of each word.
By combining lexemes and morphemes, you assemble phrases and sentences. But there are some rules to combine words, you just don’t put them in random order. A common well formed sentence may have a noun a verb and prepositions binding them as in: “Javier plays the guitar at nights”. The set of laws for order in words is called syntax.
Above the phrases and sentences, is where the beauty lies, with those blocks people create magnificent buildings, the books, poems and songs you love. In this level, a context start to exist, and the language structure exhibits a deeper meaning. We want the machines to process such context and understand that meaning.
What are the NLP people doing?
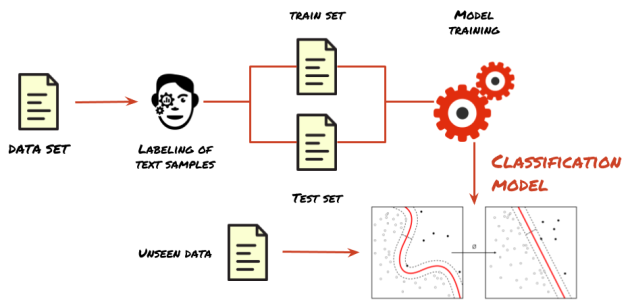
The most popular area of research is text classification, the intention behind it is to assign one label (or more) to a text. A common use of text classification is the spam detection, companies like Gmail or Outlook use it. Another great use relies on customer service support, having to check thousands of complaints from customers is not practical, as most of this comments are not clear about the complaint; text classification helps to filter the info which leads to actions. The process to apply text classification follows a common machine learning model training, you start from a data set of texts, you proceed to assign labels to each text sample, divide the data set into training and test sets, train the model (previously choosing a method that fits the problem) and then you use your model to classify unseen data.
I started the definition of NLP by giving the example of Siri and Google assistant, you must be aware of others like Cortana or Alexa, these are the focus of conversational agents area. This area (and in general all the NLP areas) intersect in common use cases with information extraction, in the last, the objective is to identify the entities involved in the text. For example, in a phrase like: “The president went to the Congress in Bogotá, to defend himself against corruption charges”, in order to understand the meaning, an algorithm need to extract the words: “president”, “Congress”, “Bogotá” and “corruption”, these words are know as entities; you could identify the entities easily as they take the form of nouns in sentences. From the text that lies between entities, an algorithm could infer relationships: “The president went to the Congress”; entities and the relationships binding them form a context. A conversational agent could use this context to answer user queries, this is close to another area: information retrieval, which works with how a machine can understand human questions and retrieve information that answer the queries and is (of course) used in search engines. The conversational agents make use of the information extraction and retrieval to chat with the user.
With the common use of NLP areas more and more applications born: calendar event detection, plagiarism detection, speech recognition, spelling check, sentiment analysis, translation from language to language, the list may grow as the research continues.
How does NLP works?
There are three common approaches to work with NLP, the first one is heuristics. With heuristics, the rules to understand the language are handcrafted; the approach works for MVP’s application, but are sensitive to concept drift and the accuracy suffer if the application scale. To work with heuristic a domain expert is required, a drawback if you think about it as an added dependency; the tackle to this is to use knowledge bases, dictionaries and thesaurus from the web, these resources are maintained by the community and free (in some cases). A common tool in the analysis with this approach are the regular expressions or regex, think about the extraction of user names in social networks post with a regex like:
"@.*"
A popular approach to NLP is the use of machine learning; by having datasets of text, a model is training to work on the desired task, some of the most common techniques are: naïve Bayes, support vector machines and conditional random fields. The conditional random fields or CRF have gained popularity outperforming Hidden Markov Models by giving relevance to the order of the words in text and the context they from. CRF have been used successfully in entity extraction tasks.
Finally deep learning with neural networks is the third approach, leveraged by the ability of neural networks to work with unstructured data.
Where can I start?
Personally I have worked with the heuristic and machine learning approaches, I used Python as programming language, its versatility to work with object oriented, functional and structured paradigms makes it a great option, also counts with a full ecosystem of packages to work in data science. Some of the tool you may use are:
- Pandas: This will be your best friend working with data, probably you are going to handle csv or json files, with pandas you could load this files and work with them in a matrix structure. It allows to make queries over the matrix, transformation, dimensionality reduction, mapping, filtering among others.
https://pandas.pydata.org/ - Numpy: Is the the tool for working with algebra and n-dimensional data structures, you will see, as you advance, words are converted into vectors and arrays and this package ease the work with such structures. https://numpy.org/
- Sklearn: This is the package for machine learning, gives you a great set of classifications algorithms, clustering methods for unsupervised learning, data preprocessing, random generation of training and testing files, evaluation functions and many more, this is the package you should dominate for the ML tasks. https://scikit-learn.org/stable/
- NTLK: Last but not the least, the ad hoc package for NLP, gives you: classification, tokenization, stemming, parsing, stop words dictionaries and many other tools to work with the areas we talk about it. https://www.nltk.org/
To read more about this topic, you could go to:
- Natural Language Processing Group – Stanford
- Named Entity Recognizer – Stanford
- Information Retrieval – Stanford
- Conditional Random Fields
- Google DialogFlow for conversational agents
Happy research!
